- 高可用01:什么是高可用系统?
- 高可用02:高可用系统设计之「架构高可用」
- 高可用03:高可用系统设计之「应用高可用」
- 高可用04:高可用系统设计之「服务高可用」
- 高可用05:高可用系统设计之「存储高可用」
- 高可用06:高可用系统设计之「其他辅助手段」
其他辅助手段
(1)异地多活
异地多活架构的关键点就是异地、多活,其中异地就是指地理位置上不同的地方,类似于“不要把鸡蛋都放在同一篮子里”;多活就是指不同地理位置上的系统都能够提供业务服务,这里的“活”是活动、活跃的意思。
异地多活架构可以分为同城异区、跨城异地、跨国异地。
同城跨区的关键在于搭建高速网络将两个机房连接起来,达到近似一个本地机房的效果。架构设计上可以将两个机房当作本地机房来设计,无须额外考虑。
跨城异地的关键在于数据不一致的情况下,业务不受影响或者影响很小,这从逻辑的角度上来说其实是矛盾的,架构设计的主要目的就是为了解决这个矛盾。
跨国异地的关键主要是面向不同地区用户提供业务,或者提供只读业务,对架构设计要求不高
异地多活架构的代价:
- 系统复杂度会发生质的变化,需要设计复杂的异地多活架构。
- 成本会上升,毕竟要多在一个或者多个机房搭建独立的一套业务系统。
异地多活的设计原则:
- 保证核心业务的异地多活
- 保证核心数据最终一致性(不需要保证实时一致性)
- 采用多种手段同步数据
- 只保证绝大部分用户的异地多活
异地多活设计步骤:
- 业务分级 - 常见的分级标准有:
- 流量大的业务:以用户管理系统为例,业务包括登录、注册、用户信息管理,其中登录的访问量肯定是最大的。
- 核心业务:以 QQ 为例,QQ 的主场景是聊天,QQ 空间虽然也是重要业务,但和聊天相比,重要性就会低一些
- 盈利业务:同样以 QQ 为例,聊天可能很难为腾讯带来收益,因为聊天没法插入广告;而 QQ 空间反而可能带来更多收益,因为 QQ 空间可以插入很多广告,因此如果从收入的角度来看,QQ 空间做异地多活的优先级反而高于 QQ 聊天了。
- 数据分类 - 常见的数据分析维度有:
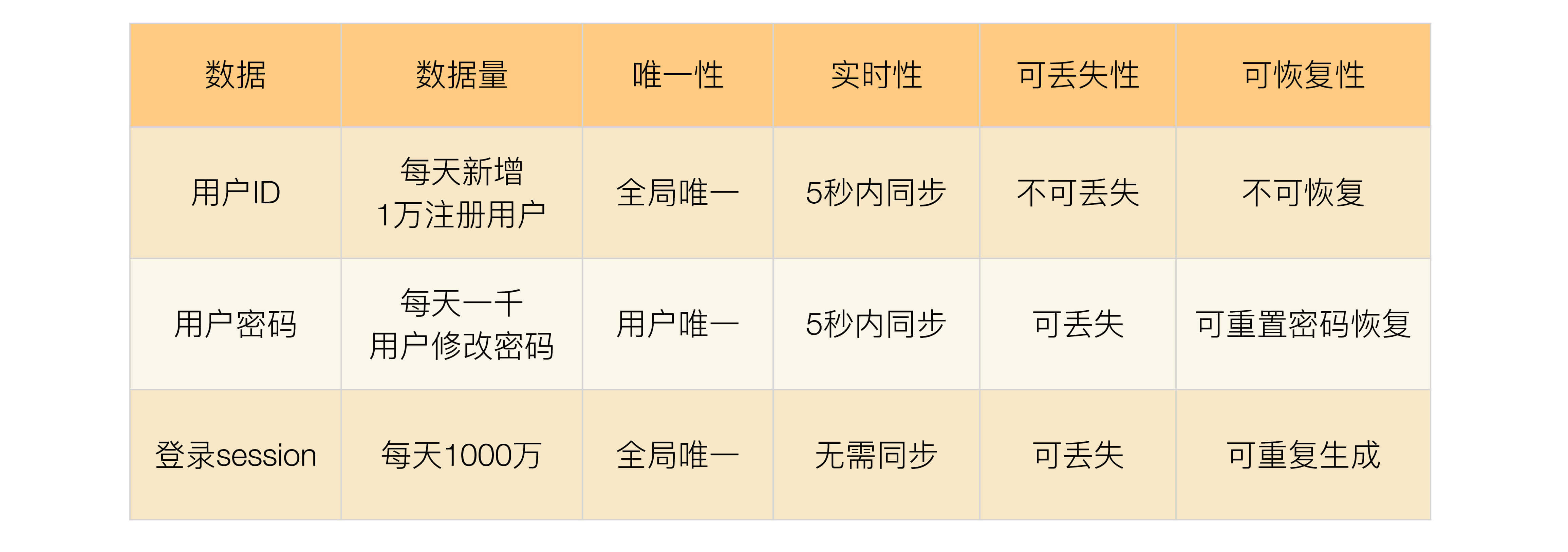
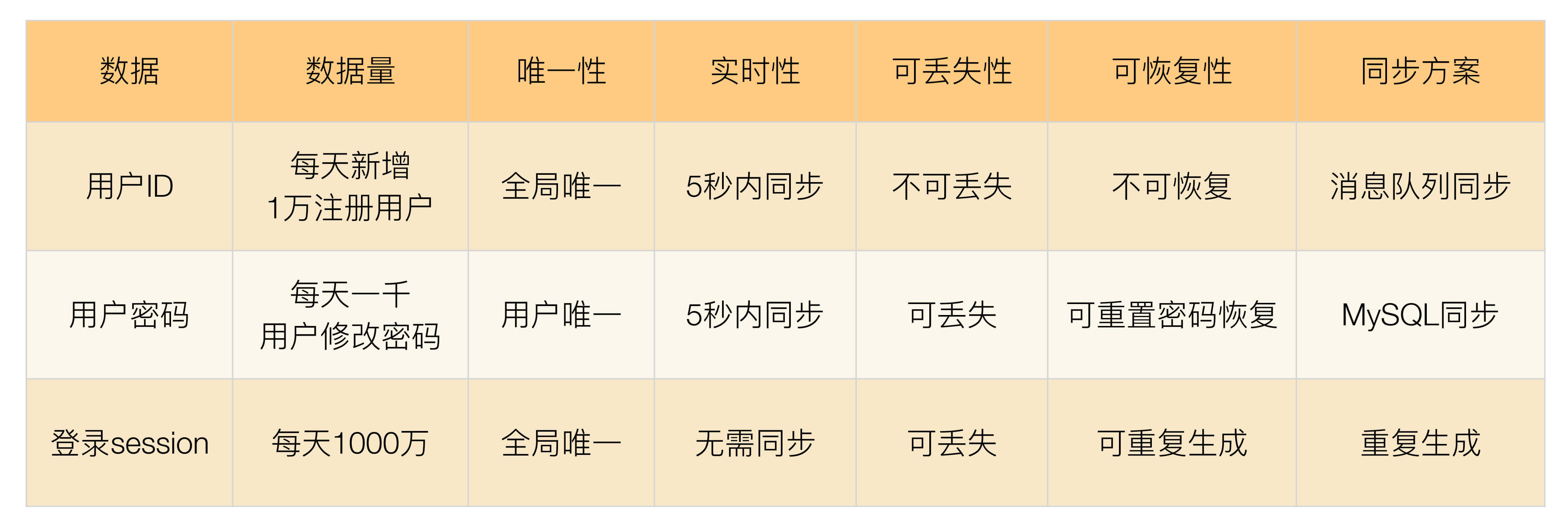
数据量:这里的数据量包括总的数据量和新增、修改、删除的量。
唯一性:唯一性指数据是否要求多个异地机房产生的同类数据必须保证唯一。例如用户 ID,如果两个机房的两个不同用户注册后生成了一样的用户 ID,这样业务上就出错了。
实时性:实时性指如果在 A 机房修改了数据,要求多长时间必须同步到 B 机房,实时性要求越高,对同步的要求越高,方案越复杂。
可丢失性:可丢失性指数据是否可以丢失。例如,写入 A 机房的数据还没有同步到 B 机房,此时 A 机房机器宕机会导致数据丢失,那这部分丢失的数据是否对业务会产生重大影响。例如,登录过程中产生的 session 数据就是可丢失的,因为用户只要重新登录就可以生成新的 session;而用户 ID 数据是不可丢失的,丢失后用户就会失去所有和用户 ID 相关的数据,例如用户的好友、用户的钱等。
可恢复性:可恢复性指数据丢失后,是否可以通过某种手段进行恢复,如果数据可以恢复,至少说明对业务的影响不会那么大,这样可以相应地降低异地多活架构设计的复杂度。
- 数据同步 - 常见的数据同步方案
存储系统同步:这是最常用也是最简单的同步方式。例如,使用 MySQL 的数据主从数据同步、主主数据同步。缺点是无法定制化,例如,无论需要同步的数据量有多大,MySQL 都只有一个同步通道。因为要保证事务性,一旦数据量比较大,或者网络有延迟,则同步延迟就会比较严重。
消息队列同步:采用独立消息队列进行数据同步,常见的消息队列有 Kafka、ActiveMQ、RocketMQ 等。适合无事务性或者无时序性要求的数据。
重复生成:数据不同步到异地机房,每个机房都可以生成数据,这个方案适合于可以重复生成的数据。例如,登录产生的 cookie、session 数据、缓存数据等。
- 异常处理 - 常见异常处理措施:
- 多通道同步:通过多种方式同步数据,例如消息队列+MySQL。
- 同步和访问结合:这里的访问指异地机房通过系统的接口来进行数据访问。例如业务部署在异地两个机房 A 和 B,B 机房的业务系统通过接口来访问 A 机房的系统获取账号信息,如下图所示。
- 日志记录:日志记录主要用于用户故障恢复后对数据进行恢复,其主要方式是每个关键操作前后都记录相关一条日志,然后将日志保存在一个独立的地方,当故障恢复后,拿出日志跟数据进行对比,对数据进行修复。
- 用户补偿:游戏中比较常见,比如对某某日无法登陆游戏的用户补偿特殊的奖励。
(2)软件质量保证
很多网站都保证 7*24 小时高可用运行,同时网站不断发布新功能吸引用户以保证在激烈的市场竞争中获得成功。许多大型网站都需要发布一到两次,而中小网站则更加频繁,一些处于快速发展期的网站甚至每天发布十几次。
不管发布的新功能是修改了一个按钮的布局还是核心交易功能,都需要再服务器上关闭原有应用,然后重新部署启动新的应用,整个过程都需要不影响用户的使用。网站的发布过程和服务器宕机效果相当,可以用服务器宕机的高可用方案来应对网站的发布。
所以,设计网站的高可用架构时,需要考虑的服务器宕机概率不是物理上的每年一两次,而是事实上的每周一两次。用户需要面对的是每周一两次的宕机故障。
这需要一套完善的流程来保证在发布的过程中用户不受到任何的影响或者说将影响降到最低:
自动化测试: Web 自动化测试技术,使用自动测试工具或脚本完成测试,比如Selenium。
自动化部署
持续部署:持续集成(jenkins、单元测试)、持续交付、持续部署【如何理解持续集成、持续交付、持续部署?】
预发布验证:开发环境>测试环境>回归测试>预发布环境>生产环境
代码版本控制:分支开发,主干发布
自动化发布
灰度发布
应用发布完成后,仍然可能会发现因为软件问题而引入的故障,这时候就需要做发布回滚,即卸载刚刚发布的软件,将上一个软件包重新发布,使系统恢复,消除故障。
大型网站的主要业务服务器集群规模非常庞大,比如:QQ 的服务器数量超过一万台。一旦发现故障,即使想要发布回滚也需要很长的时间才能完成,只能看着故障时间增加。
为了应付这种局面,大型网站会使用灰度发布模式,将集群服务器分成若干部分,每天只发布一部分服务器,观察运行稳定没有故障,第二天继续发布一部分服务器,持续几天的时间把整个集群全部发布完毕,期间如果发现问题,就只需要回滚已发布的一部分服务器即可。
【推荐阅读】
(3)系统运维和监控
“不允许没有监控的系统上线”,这是许多网站架构师在做项目上线评审的时候常说的一句话。
网站运行监控对于网站运维和架构设计优化只管重要,没有监控的网站,犹如盲人骑瞎马,夜半临深渊而不知。生死未卜,提高可用性,减少故障率就无从做起。
系统运维
Docker+Kubernetes
监控数据采集
- 用户行为日志收集
- 服务端日志收集 - Apache、Nginx 等几乎所有 Web 服务器都具备日志记录功能,只要开启日志记录即可。如果是服务器比较多,需要集中采集日志,通常会使用 Elastic 来进行收集。
- 客户端日志收集 - 利用页面嵌入专门的 JavaScript 脚本可以收集用户真实的操作行为。
- 日志分析 - 可以利用 ElasticSearch 做语义分析及搜索;利用实时计算框架 Storm、Flink 等开发日志统计与分析工具。
- 服务器性能监控 - 收集服务器性能指标,如系统负载、内存占用、CPU 占用、磁盘 IO、网络 IO 等。常用的监控工具有:Apache SkyWalking (opens new window)、Pinpoint (opens new window)等。
- 运行数据报告 - 应该监控一些与具体业务场景相关的技术和业务指标,如:缓存命中率、平均响应时延、TPS、QPS 等。
- 用户行为日志收集
监控管理
- 系统报警 - 设置阈值。当达到阈值,及时触发告警(短信、邮件、通信工具均可),通过及时判断状况,防患于未然。
- 失效转移 - 监控系统可以在发现故障的情况下主动通知应用进行失效转移。
- 自动优雅降级
- 优雅降级是为了应付突然爆发的访问高峰,主动关闭部分功能,释放部分资源,以保证核心功能的优先访问。
- 系统在监控管理基础之上实现自动优雅降级,是柔性架构的理想状态。