- 高可用01:什么是高可用系统?
- 高可用02:高可用系统设计之「架构高可用」
- 高可用03:高可用系统设计之「应用高可用」
- 高可用04:高可用系统设计之「服务高可用」
- 高可用05:高可用系统设计之「存储高可用」
- 高可用06:高可用系统设计之「其他辅助手段」
前言
本系列为本人在公司内部分享的高可用介绍,大部分内容于网上搜阅资料收集而成,参阅了极客时间的左耳听风系列以及零散的文章,主要目的并不是详细的介绍高可用,更多的是为了提供一个框架,整体上熟悉高可用是什么以及搭建高可用系统时需要注意的事项,做到熟悉框架、整体有数。
什么是高可用?
要想了解高可用这个概念,我们首先需要知道:什么是高可用?在介绍它之前,我们首先来看两个息息相关的概念。
分布式一致性
用户,在使用不同的系统或者不同的场景的时候,对于应用所着重的功能点是有不同的期望值的。
举个例子,当我们登录12306买票的时候,我们肯定不希望买到的票和别人买到的票是重复的,对于我们来说是天经地义的,但是对于购票系统来说,就有严格的一致性要求,也就是说购票系统的数据无论在天南海北的哪个售票窗口每时每刻必须都保证是准确无误的。
再说银行的转账系统,当我们转账或者从别处转入一笔钱的时候,如果金额较大,一般不会即时到账,而我们最希望的也是这笔钱能够到账而不是即时到账。那么对于银行的系统来说,最终要保证的是绝对的数据安全,即时在数据一致性上出现延时。
再比如说,我们逛京东,看到商品库存量充足,点击购买,但是其实下单的时候才会去核查系统真实的库存量,也就是说我们看到的库存量其实并不是时时刻刻都是正确的,但这个对我们其实并没有造成太大的损失。
对于分布式系统,要解决的一个重要问题就是数据的复制。在对一个副本数据进行更新的时候,必须确保也能够更新其他的副本,否则不同副本之间的数据将不一致,这就是数据的一致性。
那么如何解决这个问题?一种思路是既然是由于延时动作引起的问题,那我可以将写入的动作阻塞,直到数据复制完成后,才完成写入动作。 没错,这似乎能解决问题,而且有一些系统的架构也确实直接使用了这个思路。但这个思路在解决一致性问题的同时,又带来了新的问题:写入的性能。如果你的应用场景有非常多的写请求,那么使用这个思路之后,后续的写请求都将会阻塞在前一个请求的写操作上,导致系统整体性能急剧下降。
总体来说,我们无法找到一种能够满足分布式系统所有系统属性的分布式一致性解决方案。因此,如何既保证数据的一致性,同时又不影响系统运行的性能,是每一个分布式系统都需要重点考虑和权衡的。
强一致性
这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么(数据时时一致),用户体验好,但实现起来往往对系统的性能影响大
弱一致性
这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不久承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
最终一致性
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型
CAP和BASE理论
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
简单来说,CAP理论可以概括为:在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证**一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)**三者中的两个,另外一个必须被牺牲。
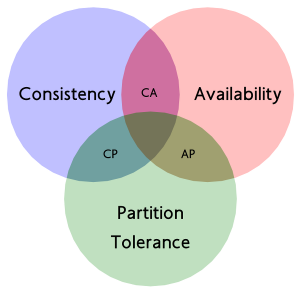
| CA | 放弃分区容错性**,**加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性(这里说的一致性是强一致性)**,**追求分区容错性和可用性,允许读取所有节点的数据,但是数据可能不一致,这是很多分布式系统设计时的选择,例如很多 NoSQL 系统就是如此 |
| CP | 放弃可用性,追求一致性和分区容错性,不能访问未同步完成的节点,失去部分可用性,基本不会选择,网络问题会直接让整个系统不可用 |
需要明确的一点是,对于一个分布式系统而言,分区容错性是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,因此必然出现子网络。而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构师往往需要把精力花在如何根据业务特点在C(一致性)和A(可用性)之间寻求平衡。
在说BASE理论之前,我想大家都很熟悉的一个属性,也是面试题必背的问题,那就是ACID,传统关系型数据库系统的事务都有 ACID 属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
事务的 ACID 属性保证了数据库的一致性,比如银行系统中,转账就是一个事务,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和构成一个完整的逻辑过程,是不可拆分的原子操作,从而保证了整个系统中的总金额没有变化。然而,这对于我们的分布式系统来说,尤其是微服务来说,这样的方式是很难满足高性能要求的。我们刚刚介绍的CAP 理论——在分布式的服务架构中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance),在现实中不能都满足,最多只能满足其中两个。
所以,为了提高性能,出现了 ACID 的一个变种—— BASE。
- **Basic Availability:基本可用。**这意味着,系统可以出现暂时不可用的状态,而后面会快速恢复。
- **Soft-state:软状态。**它是我们前面的“有状态”和“无状态”的服务的一种中间状态。也就是说,为了提高性能,我们可以让服务暂时保存一些状态或数据,这些状态和数据不是强一致性的。
- Eventual Consistency:最终一致性,系统在一个短暂的时间段内是不一致的,但最终整个系统看到的数据是一致的。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的。BASE 理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID 特性和 BASE 理论往往又会结合在一起,这就是所谓的酸碱平衡。
【推荐阅读】
高可用的定义
我们先看维基百科对于高可用的定义:
High availability (HA) is a characteristic of a system which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.
翻译过来大概是:高可用性 (HA) 是系统的一个特征,旨在确保在高于正常时间的时间内达到商定的操作性能水平,通常是正常运行时间。
高可用的量化方法——”Nines“
系统不可用也被称作系统故障,业界通常用多个 9 来衡量系统的可用性。如 QQ 的可用性为 4 个 9,即 99.99% 可用。
| |
| 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
|---|---|---|---|---|
| 90% (1个9) | 36.5 天 | 72 小时 | 16.8 小时 | 2.4 小时 |
| 95% (1.5个9) | 18.26天 | 36.53 小时 | 8.4 小时 | 1.2 小时 |
| 99% (2个9) | 3.65 天 | 7.20 小时 | 1.68 小时 | 14.4 分 |
| 99.9% (3个9) | 8.76 小时 | 43.8 分 | 10.1 分钟 | 1.44 分 |
| 99.99% (4个9) | 52.56 分 | 4.38 分 | 1.01 分钟 | 8.66 秒 |
| 99.999% (5个9) | 5.26 分 | 25.9 秒 | 6.05 秒 | 0.87 秒 |
高可用的核心原则
- 消除单点故障。意思就是说在系统的设计中对软硬件增加冗余,即使组件发生故障,也并不意味着整个系统发生故障。
- 可靠的交叉点(CrossOver)。 在冗余系统中,交叉点本身往往会成为单点故障。 这是一些不容易冗余的结点,比如域名解析,负载均衡器等。
- 对故障的检测和恢复。检测故障以及用备份的结点接管故障点。这也就是failover。
那么,我们要想设计一个高可用系统,需要注意些什么呢?要想回答这个问题,我们可以先反向考虑一下,导致系统不可用的原因有哪些呢?
导致系统不可用的原因分析
导致系统不可用的原因有两类,有计划的宕机和无计划的宕机。其中,无计划宕机有:
- 系统级的故障 – 包括主机、操作系统、中间件、数据库、网络、电源以及外围设备
- 数据和中介的故障 – 包括人员误操作、硬盘故障、数据乱了
- 还有:自然灾害、人为破坏、以及供电问题。
有计划的宕机原因有:
- 日常任务:备份,容量规划,用户和安全管理,后台批处理应用
- 运维相关:数据库维护、应用维护、中间件维护、操作系统维护、网络维护
- 升级相关:数据库、应用、中间件、操作系统、网络、包括硬件升级
我们再给它们归个类。
- 网络问题。网络链接出现问题,网络带宽出现拥塞……
- 性能问题。数据库慢 SQL、Java Full GC、硬盘 IO 过大、CPU 飙高、内存不足……
- 安全问题。被网络攻击,如 DDoS 等。
- 运维问题。系统总是在被更新和修改,架构也在不断地被调整,监控问题……
- 管理问题。没有梳理出关键服务以及服务的依赖关系,运行信息没有和控制系统同步……
- 硬件问题。硬盘损坏、网卡出问题、交换机出问题、机房掉电、挖掘机问题……
细数以上种种问题,我们会发现,高可用除了单纯的技术设计方案以外,跟外界因素也是息息相关的,甚至有些根本无法避免。而高可用的系统架构设计目标就是要保证当出现硬件故障时,服务依然可用,数据依然能够保存并被访问。
所以实现高可用的系统架构的主要手段是数据和服务的冗余备份及失效转移,一旦某些服务器宕机,就将服务切换到其他可用的服务器上;如果磁盘损坏,则从备份的磁盘读取数据。
【推荐阅读】
【文章节选】真正决定高可用系统的本质原因
从上面这些会影响高可用的SLA的因素,你看到了什么?如果你还是只看到了技术方面或是软件设计的东西,那么你只看到了冰山一角。我们再仔细想一想,那个5个9的SLA在一年内只能是5分钟的不可用时间,5分钟啊,如果按一年只出1次故障,你也得在五分钟内恢复故障,让我们想想,这意味着什么?
如果你没有一套科学的牛逼的软件工程的管理,没有牛逼先进的自动化的运维工具,没有技术能力很牛逼的工程师团队,怎么可能出现高可用的系统啊。
是的,要干出高可用的系统,这TMD就是一套严谨科学的工程管理,其中包括但不限于了:
- 软件的设计、编码、测试、上线和软件配置管理的水平
- 工程师的人员技能水平
- 运维的管理和技术水平
- 数据中心的运营管理水平
- 依赖于第三方服务的管理水平
深层次的东西则是——对工程这门科学的尊重:
- 对待技术的态度
- 一个公司的工程文化
- 领导者对工程的尊重