什么是”高内聚、松耦合“?
”高内聚、松耦合“是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。很多设计原则都是以实现代码的”高内聚、松耦合“为目的的,比如单一职责原则、基于接口而非实现编程等。
”高内聚、松耦合“可以用来指导不同粒度代码的设计与开发,比如系统、模块、类甚至是函数,为了方便理解,接下来以类作为这个设计思想的应用对象来展开讲解,其他场景可以自行类比。
在这个思想中,”高内聚“用来指导类本身的设计,”松耦合“用来指导类与类之间依赖关系的设计。不过二者并非完全独立,高内聚有助于松耦合,松耦合有需要高内聚的支持。
高内聚
所谓高内聚,就是说相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。所以单一职责原则是实现代码高内聚非常有效的设计原则。
松耦合
所谓松耦合,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动。实际上,我们之前说过的依赖注入、接口隔离、基于接口而非实现编程,都是为了实现代码的松耦合。
内聚和耦合的关系
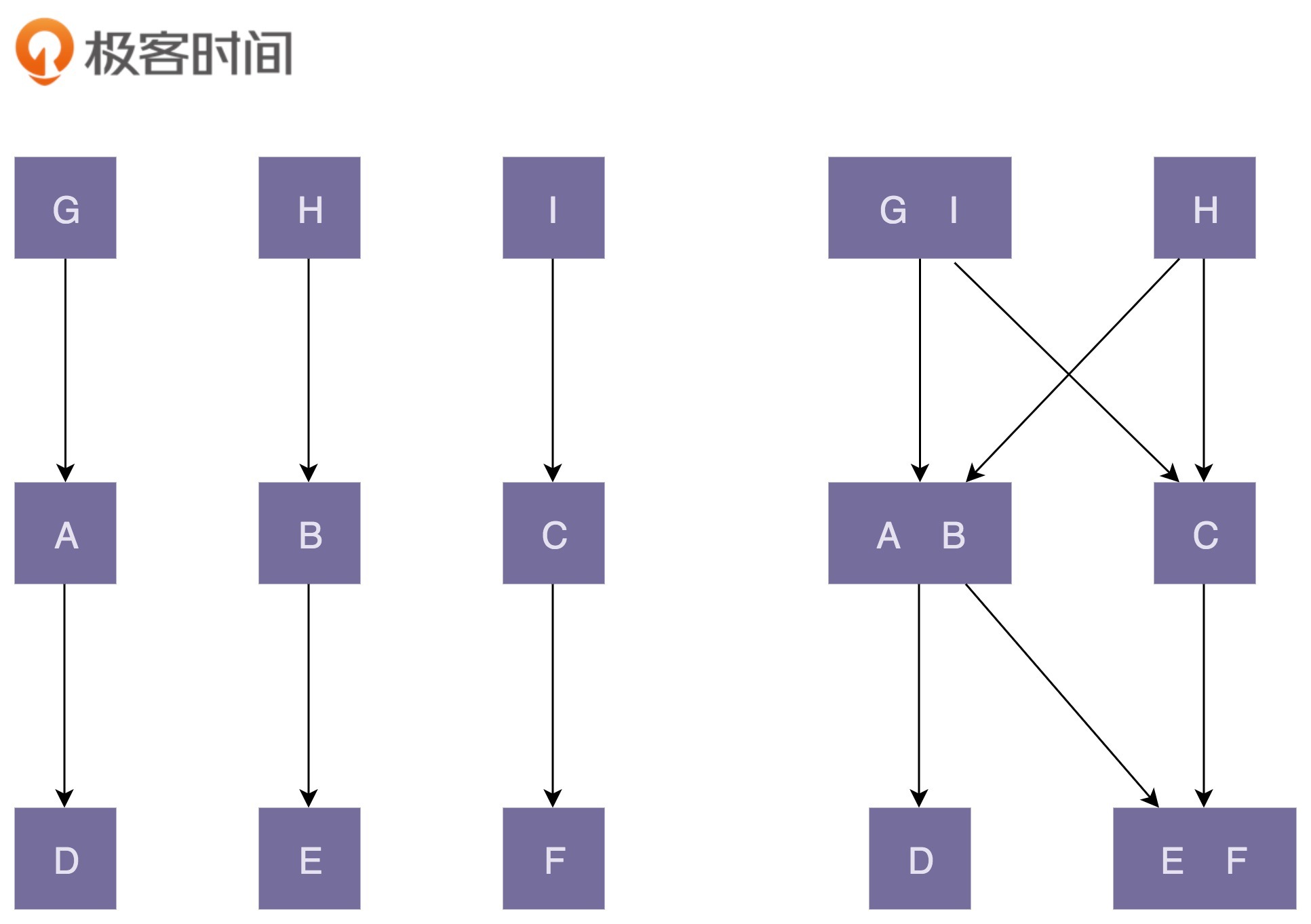
为了便于理解,上面这张图中,左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”。
迪米特法则
迪米特法则的英文翻译是:Law of Demeter,但从名字来看是完全看不出来的,它还有另外一个名字,叫做最小知识原则,英文为:The Least Knowledge Principle。
迪米特法则的英文定义为:
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
我们把它直译成中文,就是下面这个样子:
每个模块(unit)只应该了解那些与它关系密切的模块(units: only units “closely” related to the current unit)的有限知识(knowledge)。或者说,每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)。
我们再来根据实战经验来润色一下:
- 不该有直接依赖关系的类之间,不要有依赖;
- 有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。
下面结合实战,我们分别来详细讲解下这两句话。
1.不该有直接依赖关系的类之间,不要有依赖
现在有一个简化版的搜索引擎爬取网页的功能,代码中包含三个主要的类。其中,NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。
| |
这段代码虽然能用,但是有很多的设计缺陷。
NetworkTransporter作为底层网络通信类,我们希望它的功能尽可能通用而非只服务于Html,所以我们不应该直接依赖太具体的发送对象HtmlRequest
1 2 3 4 5 6 7public class NetworkTransporter { // 省略属性和其他方法... public Byte[] send(String address, Byte[] data) { //... } }HtmlDownloader类本身的设计没有问题,只需要按照NetworkTransporter的改动修改对应的入参即可
1 2 3 4 5 6 7 8 9 10 11 12public class HtmlDownloader { private NetworkTransporter transporter;//通过构造函数或IOC注入 // HtmlDownloader这里也要有相应的修改 public Html downloadHtml(String url) { HtmlRequest htmlRequest = new HtmlRequest(url); Byte[] rawHtml = transporter.send( htmlRequest.getAddress(), htmlRequest.getContent().getBytes()); return new Html(rawHtml); } }Document类问题很多:第一,构造函数中的 downloader.downloadHtml() 逻辑复杂,耗时长,不应该放到构造函数中,会影响代码的可测试性。代码的可测试性我们后面会讲到,这里你先知道有这回事就可以了。第二,HtmlDownloader 对象在构造函数中通过 new 来创建,违反了基于接口而非实现编程的设计思想,也会影响到代码的可测试性。第三,从业务含义上来讲,Document 网页文档没必要依赖 HtmlDownloader 类,违背了迪米特法则。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25public class Document { private Html html; private String url; public Document(String url, Html html) { this.html = html; this.url = url; } //... } // 通过一个工厂方法来创建Document public class DocumentFactory { private HtmlDownloader downloader; public DocumentFactory(HtmlDownloader downloader) { this.downloader = downloader; } public Document createDocument(String url) { Html html = downloader.downloadHtml(url); return new Document(url, html); } }
2.有依赖关系的类之间,尽量只依赖必要的接口
下面这段代码非常简单,Serialization 类负责对象的序列化和反序列化。
| |
假设在我们的项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。那基于迪米特法则后半部分“有依赖关系的类之间,尽量只依赖必要的接口”,只用到序列化操作的那部分类不应该依赖反序列化接口。同理,只用到反序列化操作的那部分类不应该依赖序列化接口。
根据这个思路,我们应该将 Serialization 类拆分为两个更小粒度的类,一个只负责序列化(Serializer 类),一个只负责反序列化(Deserializer 类)。拆分之后,使用序列化操作的类只需要依赖 Serializer 类,使用反序列化操作的类只需要依赖 Deserializer 类。
不知道你有没有看出来,尽管拆分之后的代码更能满足迪米特法则,但却违背了高内聚的设计思想。如果我们既不想违背高内聚的设计思想,也不想违背迪米特法则,那我们该如何解决这个问题呢?实际上,通过引入两个接口就能轻松解决这个问题:
| |
实际上,上面的的代码实现思路,也体现了“基于接口而非实现编程”的设计原则,结合迪米特法则,我们可以总结出一条新的设计原则,那就是“基于最小接口而非最大实现编程”。